如何精确转换不同RGB格式
本文来源于我在使用LCD屏幕做图像显示的时候,需要实现一个Pixel类以兼容不同RGB格式,如RGB444、RGB565、RGB888,其中就涉及到不同RGB格式之间的转换(映射)。
以RGB565转RGB888为例,一个很快就能想到的思路就是对不同的颜色分量直接做移位:
1
2
3
r8 = r5 << 3;
g8 = g6 << 2;
b8 = b5 << 3;
想法很简单,因为不同的RGB格式其实就是颜色分量的精度不一样嘛。但这样想其实是有问题的,这样转换会丢失原有的动态范围,换句话说RGB565的纯白色0xFFFF经过转换后并不等于RGB888的纯白色0xFFFFFF,而是0xF8FCF8。
精确的转换应使用r8 = round((float)r5 * 255 / 31)得到,实际的缩放因子约为8.2258,直接移位丢失了小数部分。
但我们肯定想要无浮点计算的快速实现,一种简单的实现为将原值的高位填充到低位:
1
2
v8 = v5 << 3 | v5 >> 2;
v8 = v6 << 2 | v6 >> 4;
其来源是在简单移位的基础上加上了小数部分。5bit->8bit的缩放因子8.2258的小数部分约为0.25,即>>2,6bit->8bit的缩放因子4.0476的小数部分约为0.0625,即>>4。这是最接近小数位的实现。
但实际这样做不能与浮点数转换做到一一对应,在某些位上会有1bit的误差:
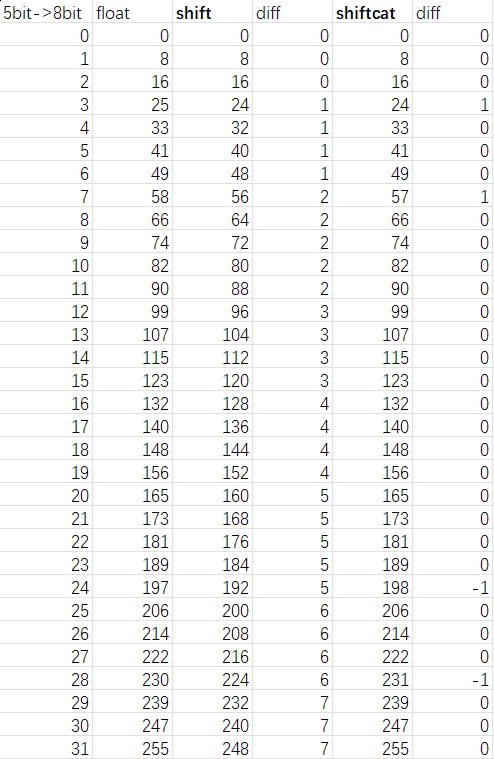
有没有办法找到最精确的转换公式呢?要求是与浮点计算一一对应,并且只用到指令周期短的运算,也就是说除法用移位实现,除数应为2^n。
幸运的是,由于定义域范围较小且都为整数,我们是可以找出这样的公式的。考虑v8 = (v5 * a + b) / c,b的作用是补足小数误差,使用暴力求解的方式搜索出公式。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
void search_most_linear()
{
constexpr int from_bit = 5;
constexpr int to_bit = 8;
constexpr int from_max = (1 << from_bit) - 1;
constexpr int to_max = (1 << to_bit) - 1;
std::cout << "The max linear conversion from " << from_bit << "bit to " << to_bit << "bit:\n";
// To = (From * a + remainder)/b, which b = 2^n
for (int b = 1; b < to_max * from_max; b *= 2)
{
for (int a = 0; a < to_max * from_max; a++)
{
for (int remainder = 0; remainder < to_max * from_max; remainder++)
{
bool is_perfect = true;
for (int from = 0; from < 1 << from_bit; from++)
{
int std_to_value = lround((double)from * to_max / from_max);
if (std_to_value != (from * a + remainder) / b)
{
is_perfect = false;
break;
}
}
if (is_perfect)
{
std::cout << "To = (From * " << a << " + " << remainder << ") / " << b << "\n";
std::cout << "The intermediate range is " << log2(b) + to_bit << "bit\n";
return;
}
}
}
}
std::cout << "Doesn't find any solution.\n";
}
于是我们可以得到精确公式:
1
2
v8 = (v5 * 527 + 23) >> 6; // 中间值范围14bit
v8 = (v6 * 259 + 33) >> 6; // 中间值范围14bit
验证一下:
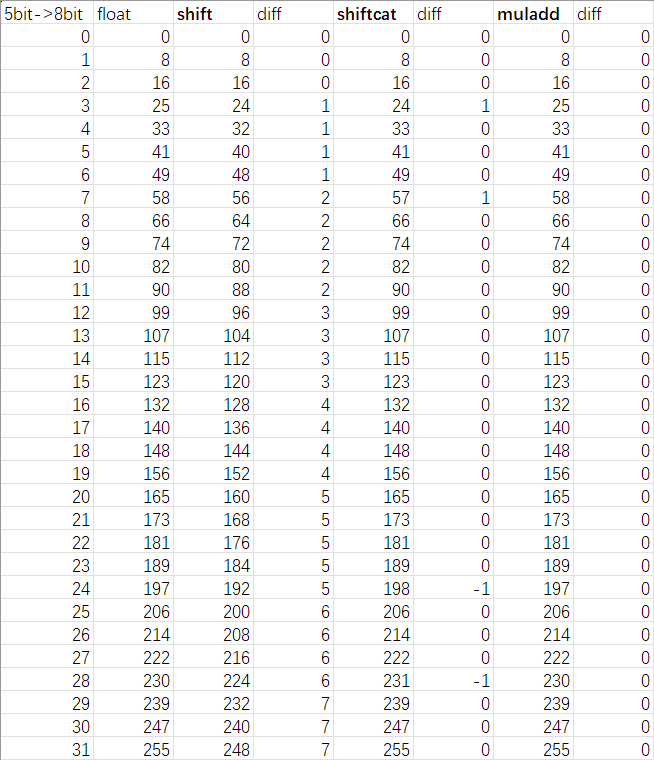
完美!
同样的我们可以找出反向转换的公式:
1
2
v5 = (v8 * 249 + 1014) >> 11; // 中间值范围16bit
v6 = (v8 * 253 + 505) >> 10; // 中间值范围16bit
在我使用的Arm Cortex-M0+平台上,开启优化后5bit->8bit精确公式的编译结果如下:
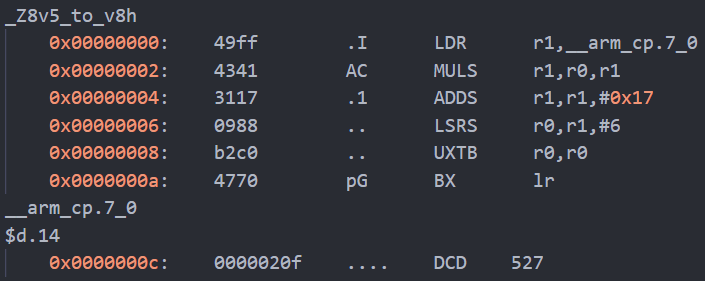
除去函数返回指令,总共为6个指令周期,其中LDR占2个周期,UXTB用于截断。
而移位填充公式编译结果如下:
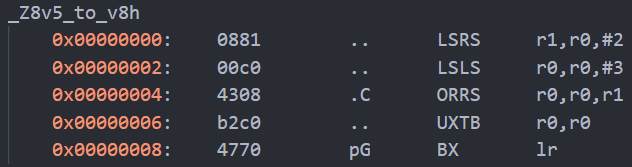
总共消耗4个指令周期,差别不大,取决于像素数量。
最后,具体使用哪个公式取决于实际要求,要求精确转换就用精确公式,若对速度要求极高且不在意略微转换误差也可以用高位填充低位的方式,甚至简单移位也是可以使用的。
参考资料